
티스토리 뷰
문제
다면체의 이름이 n개가 들어온다. 면들의 총합을 출력하면 되는 문제이다.
문제 풀이
각 다면체의 이름들의 첫 글자가 다르므로, 첫 글자만 비교하여 계산할 수 있다.
소스 코드
문제
각각 n개 m개의 variants가 들어온다. n개 중에서 1개, m개 중에서 1개를 뽑아 두 variants의 거리의 최댓값을 구하는 문제이다. 두 variants 사이의 거리는 minimal possible |i - j|, where l1 ≤ i ≤ r1 and l2 ≤ j ≤ r2로 정의한다.
문제 풀이
두 개의 variants는 서로 가장 멀리 떨어져 있을 때 최댓값을 가지므로 n개중 right가 가장 작은 값과 m개 중 left가 가장 큰 값의 거리 또는 m개 중 right가 가장 작은 값 n개 중 left가 가장 큰 값의 거리가 답이 된다.
소스 코드
문제
처음에 n개의 곡물을 가지고 있고 매일 m개의 곡물을 받아온다. 최대 n개 까지만 곡물을 저장할 수 있다. 매일 쥐가 곡물을 1개씩 먹는데 매일 쥐의 수가 1마리씩 늘어난다. 맨 처음 곡물이 0이 되는 날을 구하는 문제이다.
문제 풀이
먼저 m이 n보다 같거나 큰 경우 n 일이 지나서 쥐가 n 마리가 와서 곡물을 먹는 게 최소 일자이다. m이 n보다 작은 경우 x일이 지났을 때 곡물이 0이 됐다고 한다면 x + k (k는 자연수) 일이 지났을 때도 곡물이 0이 된다. 따라서 parametric search 를 이용하여 답을 찾을 수 있다. n-m <= (x-m)(x-m+1)/2 식을 유도할 수 있고 이분 탐색을 이용한다. 처음에는 right값이 1e18로 커질수 있어서 log를 이용해서 답을 구했지만, 실수 오차 때문에 틀리고 파이썬으로 구현하였다. 생각해보면 우변이 2e18보다 크면 무조건 가능이기 때문에 right를 2e9로 정하고 푸는 것이 가능하다.
소스 코드
문제
열린 괄호와 닫힌 괄호로 이루어진 문자열이 주어지고, 여기서 임의로 문자를 삭제하여 RSBS를 만들 수 있는 경우의 수를 세는 문제이다.
RSBS란 (()) 처럼 n개의 열린 괄호 뒤에 n개의 닫힌 괄호가 오는 문자열이다.
문제 풀이
먼저 x개의 열린 괄호 뒤에 y개의 닫힌 괄호가 붙어 있고 맨 마지막으로 열린 괄호를 항상 사용할 때 몇 개의 RSBS를 만들 수 있는지에 대한 문제를 먼저 풀어 보자.

예시로 코드포스 에디토리얼 사진을 가지고 왔다. 해당 그림에서 1의 개수가 열린 괄호의 수 0의 개수가 닫힌 괄호의 수일 때 마지막 열린 괄호에 0을 하나 할당하고, 나머지 0과 1을 아무렇게나 뿌린 다음 0과 매칭되는 열린 괄호, 1과 매칭되는 닫힌 괄호들만 체크하면 RSBS가 된다. 왜냐하면, 먼저 1의 개수는 열린 괄호 개수 만큼 있었고 이 중 z개가 닫힌 괄호랑 매칭되었다고 해보자. 그렇다면 x-z개는 열린 괄호랑 매칭되었고, 0이랑 매칭된 열린 괄호의 수는 x-(x-z)개 이므로 열린 괄호의 수와 닫힌 괄호의 수가 같다. 또한 열린 괄호는 항상 닫힌 괄호보다 왼쪽에 있으므로 RSBS를 만들 수 있다.
따라서 모든 열린 괄호 위치 i에서 [0,i]열린 괄호의 개수 = x, (i,n)닫힌 괄호의 개수 y 를 구해 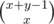 를 계산하는 것으로 답을 구할 수 있다. 모듈라 계산이 있으므로 페르마 소정리를 이용해서 푼다.
를 계산하는 것으로 답을 구할 수 있다. 모듈라 계산이 있으므로 페르마 소정리를 이용해서 푼다.
소스 코드
문제
초기{1, 2, ..., n}순열에서 쿼리마다 1쌍의 원소를 스왑하고 inversion의 수를 출력하는 문제이다.
inversion은 1 ≤ i < j ≤ n and ai > aj.인 원소 쌍을 말한다.
문제 풀이
임의로 \(\{5,3,6,8,1,7,9,2,10,4\}\) 이라는 순열이 있다고 해보자. 현재 inversion의 개수는 17개 이다. \(tree[i]=(1 \le j<i) \:a[j]<a[i] \:인\: 개수\)라고 정의 하면 다음과 같이 테이블을 그릴 수 있다.
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
a[i] |
5 |
3 |
6 |
8 |
1 |
7 |
9 |
2 |
10 |
4 |
tree[i] |
0 |
0 |
2 |
3 |
0 |
4 |
6 |
1 |
8 |
3 |
여기서 4번과 7번을 스왑한다고 하면 먼저 4번이 사라진다고 생각해보자. 그렇다면
1. 4번 왼쪽으로 a[4]보다 큰 값의 수 만큼 inversion 감소
2. 4번 오른쪽으로 a[4]보다 작은 값의 수 만큼 inversion 감소
임을 알 수 있다. 마찬가지로 7번이 삭제되면
1. 7번 왼쪽으로 a[7]보다 큰 값의 수 만큼 inversion 감소
2. 7번 오른쪽으로 a[7]보다 작은 값의 수 만큼 inversion 감소
1. 4번 왼쪽으로 a[7]보다 큰 값의 수 만큼 inversion 증가
2. 4번 오른쪽으로 a[7]보다 작은 값의 수 만큼 inversion 증가
마찬가지로 7번 자리에 a[4]를 넣으면
1. 7번 왼쪽으로 a[4]보다 큰 값의 수 만큼 inversion 증가
2. 7번 오른쪽으로 a[4]보다 작은 값의 수 만큼 inversion 증가
이다. k번 왼쪽으로 a[k]보다 큰 값의 수는 \(k-1-tree[k]\) 이고, k번 오른쪽으로 a[k]보다 작은 값의 수는 \(a[k]-1-tree[k]\) 로 구할 수 있다.
따라서 tree자료 구조를 bit의 각각의 노드를 bst로 구현하는 것으로 만들 수 있다. stl set에서는 key값보다 작은 값을 구하는 함수가 없으므로 직접 treap을 만들어 구현하였다.
소스 코드
'PS > Codeforces' 카테고리의 다른 글
| Codeforces Round #407 (Div. 2) (0) | 2017.04.07 |
|---|---|
| Codeforces Round #405 (rated, Div. 2, based on VK Cup 2017 Round 1) (0) | 2017.03.31 |